
Setup and Walk-through#
Obtaining and Running the Code#
In the previous homework, we dealt with a streaming application that compressed only one picture. For this homework, we will use the same application, except that it will take a video stream instead of a single picture. You can run Walk-through on the host computer. But note that you need to run the code for homework submission on the Ultra96.
Clone the
ese532_coderepository using the following command:git clone https://github.com/icgrp/ese532_code.git
If you already have it cloned, pull in the latest changes using:
cd ese532_code/ git pull origin master
The code you will use for homework submission is in the
hw3directory. The directory structure looks like this:hw3/ assignment/ Makefile Walkthrough.cpp common/ App.h Constants.h Stopwatch.h Utilities.h Utilities.cpp baseline/ App.cpp Compress.cpp Differentiate.cpp Filter.cpp Scale.cpp coarse_grain/ ... pipeline_2_cores/ ... cdc_parallel/ ... data/ Input.bin Golden.bin
There are four parts to the homework. You can build all of them by executing
make allin thehw3/assignmentdirectory. You can build separately by:make baseand run./baseto run the baseline project.make coarseand run./coarseto run the coarse-grain project.make pipeline2and run./pipeline2to run the pipeline project on 2 cores.make cdcand run./cdcto run the data-parallel CDC you will implement on 4 cores.
The
datafolder contains the input data,Input.bin, which has 100 frames of size \(960\) by \(540\) pixels, where each pixel is a byte.Golden.bincontains the expected output.base,coarseandpipeline2uses this file to see if there is a mismatch between your program’s output and the expected output.cdcusesprince.txtfrom thedatafolder as an input.golden.txthas the expected output cdc will produce.The
assignment/commonfolder has header files and helper functions used by the four parts.You will mostly be working with the code in the rest of the folders.
Working with Threads#
Basics#
Consider the following code:
#include <iostream>
#include <thread>
void my_function(int a, int b, int&c) {
c = a + b;
}
int main() {
int a = 2;
int b = 3;
int c;
my_function(2, 3, c);
std::cout << "a+b=" << c << std::endl;
}
What thread do you think this code is running on? Let’s find out. Adding a little bit more to the code:
#include <iostream>
#include <thread>
// gets the thread id of the main thread
std::thread::id main_thread_id = std::this_thread::get_id();
// checks if running on main thread using the id
void is_main_thread() {
if ( main_thread_id == std::this_thread::get_id() )
std::cout << "This is the main thread." << std::endl;
else
std::cout << "This is not the main thread." << std::endl;
}
void my_function(int a, int b, int&c) {
c = a + b;
}
int main() {
int a = 2;
int b = 3;
int c;
my_function(2, 3, c);
std::cout << "a+b=" << c << std::endl;
is_main_thread();
}
The output is:
a+b=5
This is the main thread.
Can we be really sure? Let’s add a little bit more:
#include <iostream>
#include <thread>
// gets the thread id of the main thread
std::thread::id main_thread_id = std::this_thread::get_id();
// checks if running on main thread using the id
void is_main_thread() {
if ( main_thread_id == std::this_thread::get_id() )
std::cout << "This is the main thread." << std::endl;
else
std::cout << "This is not the main thread." << std::endl;
}
void my_function(int a, int b, int&c) {
c = a + b;
}
int main() {
int a = 2;
int b = 3;
int c;
my_function(a, b, c);
std::cout << "a+b=" << c << std::endl;
is_main_thread();
// create a new thread, note it's not running
// anything yet.
std::thread th;
// construct the thread to run is_main_thread
// note, as soon as you construct it, the thread
// starts running.
// You could create and run at the same time
// by writing: std::thread th(is_main_thread);
th = std::thread(is_main_thread);
// wait for the thread to finish.
th.join();
}
The output is:
a+b=5
This is the main thread.
This is not the main thread.
From the above, we learned:
#include <thread>to use thread.don’t construct a thread if you don’t want to run it immediately, i.e. just declare it.
thread starts running as soon as we construct it, i.e. give it a function to run.
th.join()is a blocking call and waits for the thread to finish at the point of the program where it’s called.we are running on the
mainthread by default.
By default, the linux scheduler will schedule our threads into one of these cores. What if we know what we are doing and want full control over assigning a specific thread to run on a specific core? Let’s learn how to do that.
We have given you two functions:
void pin_thread_to_cpu(std::thread &t, int cpu_num);
void pin_main_thread_to_cpu0();
They are declared and defined in common/Utilities.h and
common/Utilities.cpp. Adding to our previous example:
#include <iostream>
#include <thread>
#include "Utilities.h"
// gets the thread id of the main thread
std::thread::id main_thread_id = std::this_thread::get_id();
// checks if running on main thread using the id
void is_main_thread() {
if ( main_thread_id == std::this_thread::get_id() )
std::cout << "This is the main thread." << std::endl;
else
std::cout << "This is not the main thread." << std::endl;
}
void my_function(int a, int b, int&c) {
c = a + b;
}
int main() {
// Assign main thread to cpu 0
pin_main_thread_to_cpu0();
int a = 2;
int b = 3;
int c;
my_function(a, b, c);
std::cout << "a+b=" << c << std::endl;
is_main_thread();
// create a new thread, note it's not running
// anything yet.
std::thread th;
// construct the thread to run is_main_thread
// note, as soon as you construct it, the thread
// starts running.
// You could create and run at the same time
// by writing: std::thread th(is_main_thread);
th = std::thread(is_main_thread);
// Assign our thread to core 1.
pin_thread_to_cpu(th, 2); // threads 0 and 1 on most machines (2 hyperthreads per core) are the same core
// wait for the thread to finish.
th.join();
}
Note
The
pin_thread_to_cpuAPIs we have given you, only works on Linux. For MacOS and Windows, we let the scheduler choose the core. So if you are prototyping on your local machine, keep it in mind.Also note how in Fig. 14 there are 2 hyper-threads per core on x86 processors. The
cpu_numargument inpin_thread_to_cpurefers to the index number of the hyper-thread. Hence, for instance, if you want to run a thread on core 0 and one on core 1, you should pin the threads to either 0 and 2, or 1 and 3. This will ensure that each thread is run on a separate core. Otherwise, multiple threads on the same core will share resources and may affect performance. To see the CPU topology in your PC, dolstopo.In homework submission, you need to run the code on Ultra96’s ARM. Note that there is no hyper-thread on ARM, so the core indices of 0 and 1 are used for
pin_thread_to_cputo access two different physical cores.
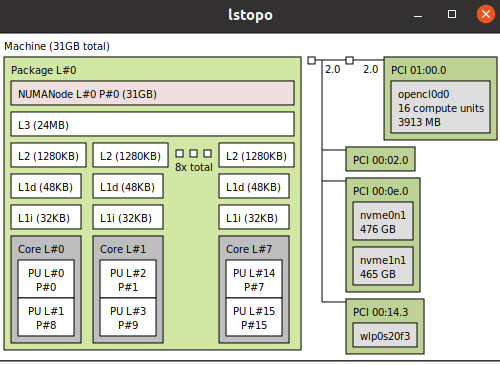
Fig. 14 An 8-core x86 processor with 2 hyper-threads#
Last thing we need to know is how to pass function and their arguments to threads? Modifying our example:
#include <iostream>
#include <thread>
#include "Utilities.h"
// gets the thread id of the main thread
std::thread::id main_thread_id = std::this_thread::get_id();
// checks if running on main thread using the id
void is_main_thread() {
if ( main_thread_id == std::this_thread::get_id() )
std::cout << "This is the main thread." << std::endl;
else
std::cout << "This is not the main thread." << std::endl;
}
void my_function(int a, int b, int&c) {
c = a + b;
std::cout << "From thread id:"
<< std::this_thread::get_id()
<< " a+b=" << c << std::endl;
}
int main() {
// Assign main thread to cpu 0
pin_main_thread_to_cpu0();
int a = 2;
int b = 3;
int c;
my_function(a, b, c);
is_main_thread();
// create a new thread, note it's not running
// anything yet.
std::thread th;
// construct the thread to run is_main_thread
// note, as soon as you construct it, the thread
// starts running.
// You could create and run at the same time
// by writing: std::thread th(is_main_thread);
th = std::thread(is_main_thread);
// Assign our thread to core 1.
pin_thread_to_cpu(th, 2);
// wait for the thread to finish.
th.join();
std::thread th2(&my_function, a, b, std::ref(c));
th2.join();
}
The output is:
From thread id:0x114275dc0 a+b=5
This is the main thread.
This is not the main thread.
From thread id:0x700001055000 a+b=5
From the above, we learned:
the first argument to constructing a thread is a callback function. This callback can be a function object (as we see in
th), a function pointer (as we see inth2) or a lambda function.the rest of the arguments are the inputs to the function. They are passed-by-value by default (i.e.
aandbare copied). Hence, if you need to pass something by reference (as we seeint& cinmy_function), you have to wrap it instd::ref.
This concludes everything you need to know about std::threads to
complete this homework. You can run the full walk-through by
make walkthrough and ./walkthrough.
Coarse-grain#
The coarse-grain part of the homework shows you how you can process
a data parallel function with threads. We show how you change the
Scale function to process it with two threads:
void Scale_coarse(const unsigned char *Input, unsigned char *Output, int Y_Start_Idx, int Y_End_Idx)
{
for (int Y = Y_Start_Idx; Y < Y_End_Idx; Y += 2)
{
for (int X = 0; X < INPUT_WIDTH_SCALE; X += 2)
{
Output[(Y / 2) * INPUT_WIDTH_SCALE / 2 + (X / 2)] = Input[Y * INPUT_WIDTH_SCALE + X];
}
}
}
From the code, you can see that we added two additional arguments at the function signature, which is then used in the for loop. This helps us realize the data parallel behavior of the function and let multiple threads work on it:
...
for (int Frame = 0; Frame < FRAMES; Frame++)
{
std::vector<std::thread> ths;
ths.push_back(std::thread(&Scale_coarse, Input_data + Frame * FRAME_SIZE, Temp_data[0], 0, INPUT_HEIGHT_SCALE / 2));
ths.push_back(std::thread(&Scale_coarse, Input_data + Frame * FRAME_SIZE, Temp_data[0], INPUT_HEIGHT_SCALE / 2, INPUT_HEIGHT_SCALE));
pin_thread_to_cpu(ths[0], 0);
pin_thread_to_cpu(ths[1], 2);
for (auto &th : ths)
{
th.join();
}
...
As we can see from the code above, two threads are launched in parallel. One
processes indices [0, 270) and the other processes [270, 540).
If you wanted to use three threads, you can split the indices as [0,180),
[180, 360) and [360, 540) and invoke another thread and pin it to cpu 3.
Pipeline#
The pipeline part of the homework shows you how you can orchestrate the launching of threads and achieve pipeline parallelism. Start reading from the main function, where we launch a process on cpu 0:
for (int Frame = 0; Frame < FRAMES + 2; Frame++)
{
core_0_process(std::ref(Size), Frame, Input_data, Temp_data, Output_data);
}
Following a top-down approach, look into core_0_process function:
void core_0_process(int &Size,
int Frame,
unsigned char *Input_data,
unsigned char **Temp_data,
unsigned char *Output_data)
{
static unsigned char temp_core_0[FRAME_SIZE];
static unsigned char *Input_data_core_0 = temp_core_0;
std::thread core_1_thread;
if (Frame < FRAMES + 1)
{
// current core (core 0) spins up process on core 1
core_1_thread = std::thread(&core_1_process,
Frame,
Input_data,
Temp_data);
pin_thread_to_cpu(core_1_thread, 2);
}
// core 0 does its job
if (Frame > 1)
{
Filter_vertical(Input_data_core_0, Temp_data[2]);
Differentiate(Temp_data[2], Temp_data[3]);
Size = Compress(Temp_data[3], Output_data);
}
// waits for core 1 to finish
if (Frame < FRAMES + 1)
{
core_1_thread.join();
}
unsigned char *Temp = Temp_data[1];
Temp_data[1] = Input_data_core_0;
Input_data_core_0 = Temp;
}
Pay special attention to the guards—if (Frame < FRAMES + 1) and
if (Frame > 1), and figure out if a code executes or not or
is waiting on another core to finish. Keep following the code
like this and you will realize how we mapped the functions
for the pipelining on 2 cores part of the
homework. In summary:
for pipelining on 2 cores, we map
Scaleand parts ofFilteron core 1 and then the rest ofFilter,DifferentiateandCompresson core 0.if you wanted to map on 3 cores, you could map
Scaleon core 2,Filter_horizontalon core 1, andFilter_vertical,DifferentiateandCompresson core 0.
You will also realize how the data flows and how the pipeline
fills and drains. Lastly, pay special attention to the static in
static unsigned char of the processes in the pipeline code.
Remember that static keyword in a block scope changes the
storage class of a variable, i.e. the lifetime of the variable
is until the program stops executing. This is especially important
since being able to use old data while new data is being produced
is key to achieving the pipeline parallelism.
Monitoring Processes using top#
When you run the code on the Ultra96, you can use top to monitor the processes running on your system.
You can monitor the core usage in top by pressing 1.
Fig. 15 top on Ultra96 showing core usage#
Performance Counter Statistics using Perf#
In hw2, two methods are suggested to measure latency: instrumentation-based profiling and gprof. In hw3, a new method using Perf is proposed. To go through the following steps, you need to ‘cd’ to hw2 folder and probably need to install ‘perf’ on the board.
ARM has a dedicated Performance Monitor Unit (PMU) that can give you the number of cycles
your program takes to run (read more about PMU here).
We can use perf to get the performance counter statistics of your program (read these slides to learn more about perf).
Run perf as follows (make perf in the supplied Makefile):
sudo perf stat ./rendering
You should see the following output:
[stahmed@macarena hw2_profiling_tutorial]$ make perf
g++ -DWITH_TIMER -Wall -g -O2 -Wno-unused-label -I/src/sw/ -I/src/host/ -o rendering ./src/host/3d_rendering_host.cpp ./src/host/utils.cpp ./src/host/check_result.cpp ./src/sw/rendering_sw.cpp
Executable rendering compiled!
Running perf stat...
3D Rendering Application
Total latency of projection is: 125316 ns.
Total latency of rasterization1 is: 136611 ns.
Total latency of rasterization2 is: 2.29206e+06 ns.
Total latency of zculling is: 244155 ns.
Total latency of coloringFB is: 146167 ns.
Total time taken by the loop is: 3.48606e+06 ns.
---------------------------------------------------------------
Average latency of projection per loop iteration is: 39.2594 ns.
Average latency of rasterization1 per loop iteration is: 42.7979 ns.
Average latency of rasterization2 per loop iteration is: 718.065 ns.
Average latency of zculling per loop iteration is: 76.4897 ns.
Average latency of coloringFB per loop iteration is: 45.7917 ns.
Average latency of each loop iteration is: 1092.12 ns.
Writing output...
Check output.txt for a bunny!
Performance counter stats for './rendering':
6.36 msec task-clock # 0.953 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
163 page-faults # 0.026 M/sec
17,322,039 cycles # 2.722 GHz
39,090,159 instructions # 2.26 insn per cycle
5,358,366 branches # 842.109 M/sec
56,019 branch-misses # 1.05% of all branches
0.006679970 seconds time elapsed
0.006685000 seconds user
0.000000000 seconds sys
From the above output, we can see that our program took \(17,322,039\) cycles at \(2.722\) GHz. We can use these numbers to find the run time of our program, which is \(17322039/2.722\) \(\approx\) \(6.36\) milli seconds which agrees with the \(6.36\) msec reported by perf too. Note that perf used the “task-clock” (system timer) to report the latency in seconds, and used the PMU counter to report the latency in cycles. The PMU counter runs at the same frequency as the cpu, which is \(2.722\) GHz, whereas the system timer runs at a much lower frequency (in the MHz range).
Now that we have shown you three approaches for measuring latency, a natural question is when do you use either of these methods?
Use Instrumentation-based Profiling with Timers or Profiling using GNU gprof when you want to find individual latencies of your functions.
Use profiling/perf when you just want to know the total latency (either in seconds or cycles) of your program. When you don’t have
perfavailable in your system, you can also runtime executable-nameto get the total time your program takes to run.
However, the above answer is too simple. The application we showed you
is slow enough for std::chrono to measure accurately. When the resolution of your system timer is not fine-grained
enough, or your function is too fast, you should measure the function for a longer period of time (see the spin loop section from here). Alternatively,
that’s where the PMU offers more accuracy. Since the PMU runs at the same
frequency as the CPU, it can measure any function. However, you will
have to isolate your functions and create separate programs to use
the PMU through perf. There is no stopwatch-like user API for the PMU
counter.
For our application above, we saw that the total runtime reported by task-clock and PMU counter doesn’t differ. Hence, it doesn’t matter which approach you use in this case. If you want to get the latencies
of individual function in cycles instead, you can just use your
measured time with the clock frequency to figure out the cycles.
Alternatively you could get the fraction of time spent by your function
and use the total number of cycles from perf stat.